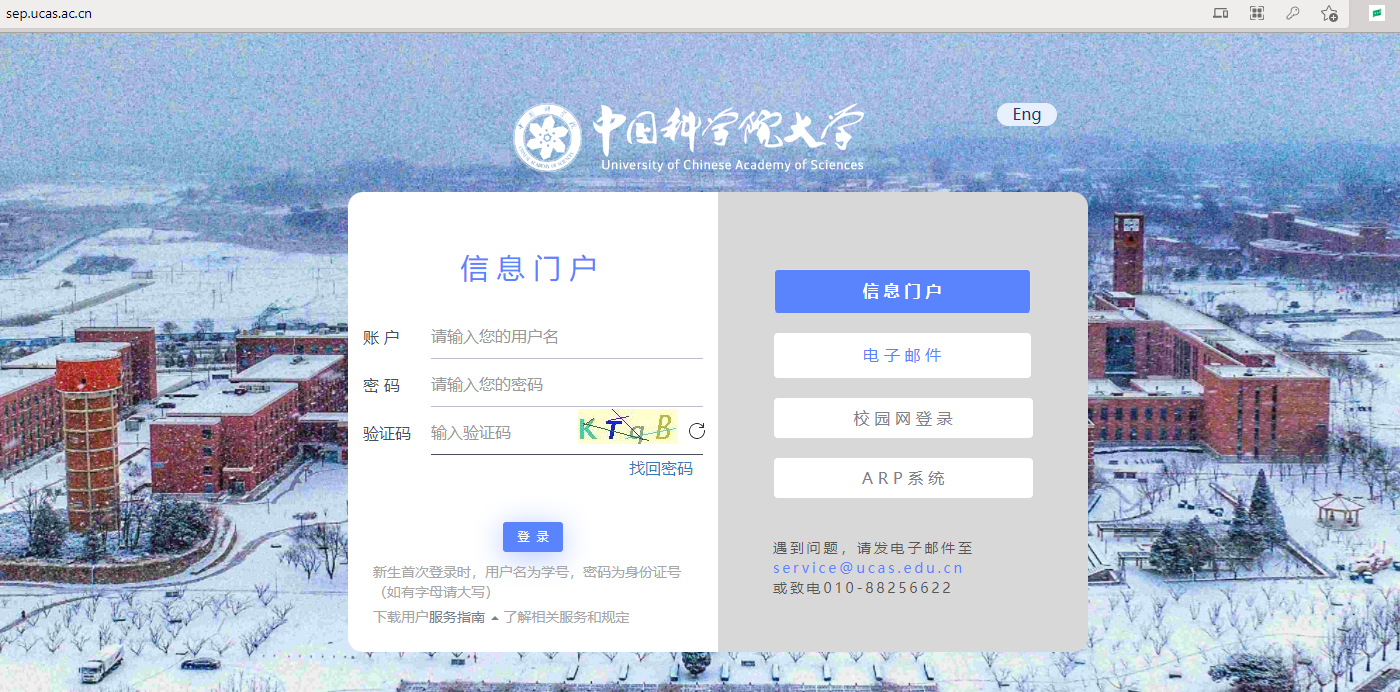
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
| '''
project: 基于Python的UCAS课程网站课件下载程序
author: Northfourta
dependent libraries:
1. requests;
2. BeautifulSoup4;
3. Image;
4. os
date: 2022/01/22
'''
import requests
from bs4 import BeautifulSoup
from PIL import Image
import os
class Ucas_Crawler:
'''
基于Python的UCAS课程网站课件下载程序
'''
def __init__(self, certCode_url, post_url, logined_url):
self.certCode_url = certCode_url
self.post_url = post_url
self.logined_url = logined_url
self.session = requests.Session()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
def get_certCode(self):
'''
得到验证码
'''
codePic = self.session.get(self.certCode_url, headers=self.headers)
with open('codePic.jpg', 'wb') as f:
f.write(codePic.content)
f.close()
img = Image.open('codePic.jpg')
img.show()
certCode = input('请输入验证码:')
return certCode
def login_in(self, certCode):
'''
登陆网站
'''
name = input('请输入用户名:')
pwd = input('请输入密码:')
post_data = {
'userName': name,
'pwd': pwd,
'certCode': certCode,
'sb': 'sb'
}
self.session.post(url=self.post_url, data=post_data, headers=self.headers)
login_page = self.session.get(url=self.logined_url, headers=self.headers)
soup_login = BeautifulSoup(login_page.text, 'html.parser')
if login_page.status_code == 200:
print('sep登陆成功!')
portal_url = 'http://sep.ucas.ac.cn' + soup_login.find_all(name='a', attrs={'title': '课程网站'})[0]['href']
return portal_url
def Course_Info(self, portal_url):
'''
获取选课信息
'''
response = self.session.get(portal_url, headers=self.headers)
url = BeautifulSoup(response.content, 'html.parser').find_all(name = 'h4')[0].a['href']
soup = BeautifulSoup(self.session.get(url=url, headers=self.headers).content, 'html.parser')
url_course = soup.find_all(name='a', attrs={'title': '我的课程 - 查看或加入站点'})[0]['href']
re = BeautifulSoup(self.session.get(url_course, headers=self.headers).content, 'html.parser')
list_course = re.find_all(name='tr')
print('你当前已选课程如下:\n -----------------------------------------------')
i = 0
url_course = []
name_course = []
for course in list_course:
if len(course.find_all(name='a', attrs={'target': '_top'})) > 0:
i += 1
content = course.find_all(name='a', attrs={'target': '_top'})[0]
print(str(i) + '. ' + content['title'].split(' ')[-1])
name_course.append(content['title'].split(' ')[-1])
url_course.append(content['href'])
print('-----------------------------------------------')
return url_course, name_course
def download_file(self, url_courses, name_courses):
string = input('请输入想要更新课件资源的课程编号(如选择多门课程,请使用空格间隔):')
dirs = input('请输入想要将资源下载到的位置(形式:”D:\\Release\\bin“):')
sect_list = list(map(int, string.split(' ')))
for sect in sect_list:
dir = dirs + '\\' + name_courses[sect-1]
if not os.path.exists(dir):
os.makedirs(dir)
current_course = BeautifulSoup(self.session.get(url_courses[sect-1], headers=self.headers).content, 'html.parser')
url_course = current_course.find_all(name='a', attrs={'title': '资源 - 上传、下载课件,发布文档,网址等信息'})[0]['href']
resource = BeautifulSoup(self.session.get(url_course, headers=self.headers).text, 'lxml')
for ppt in resource.find_all(name='a', attrs={'title': 'PowerPoint ', 'target': '_self'}):
link = ppt['href']
try:
filename = dir + '\\' + ppt.find(name='span', attrs={'class': 'hidden-sm hidden-xs'}).string
print(filename)
with open(filename, 'wb') as f:
f.write(self.session.get(link, headers=self.headers).content)
f.close()
except AttributeError:
continue
for ppt in resource.find_all(name='a', attrs={'title': 'Power Point', 'target': '_self'}):
link = ppt['href']
try:
filename = dir + '\\' + ppt.find(name='span', attrs={'class': 'hidden-sm hidden-xs'}).string
print(filename)
with open(filename, 'wb') as f:
f.write(self.session.get(link, headers=self.headers).content)
f.close()
except AttributeError:
continue
for pdf in resource.find_all(name='a', attrs={'title': 'PDF', 'target': '_blank'}):
link = pdf['href']
try:
filename = dir + '\\' + pdf.find(name='span', attrs={'class': 'hidden-sm hidden-xs'}).string
print(filename)
with open(filename, 'wb') as f:
f.write(self.session.get(link, headers=self.headers).content)
f.close()
except AttributeError:
continue
for word in resource.find_all(name='a', attrs={'title': 'Word ', 'target': '_self'}):
link = word['href']
try:
filename = dir + '\\' + word.find(name='span', attrs={'class': 'hidden-sm hidden-xs'}).string
print(filename)
with open(filename, 'wb') as f:
f.write(self.session.get(link, headers=self.headers).content)
f.close()
except AttributeError:
continue
for rar in resource.find_all(name='a', attrs={'title': '未知类型', 'target': '_self'}):
link = rar['href']
try:
filename = dir + '\\' + rar.find(name='span', attrs={'class': 'hidden-sm hidden-xs'}).string
print(filename)
with open(filename, 'wb') as f:
f.write(self.session.get(link, headers=self.headers).content)
f.close()
except AttributeError:
continue
def main(self):
certCode = self.get_certCode()
portal_url = self.login_in(certCode)
url_course, name_course = self.Course_Info(portal_url)
self.download_file(url_course, name_course)
if __name__ == '__main__':
certCode_url = 'http://sep.ucas.ac.cn/changePic'
post_url = 'http://sep.ucas.ac.cn/slogin'
logined_url = 'https://sep.ucas.ac.cn/appStore'
crawler = Ucas_Crawler(certCode_url, post_url, logined_url)
crawler.main()
|