原神启动!原批变身!恰好把之前抽的雷神培养一下,正好没有专武,想着把鱼叉弄一下。自己又不想钓鱼,正好就试着把原神自动钓鱼项目(基于深度强化学习的原神自动钓鱼AI) 复现一下 ,于是便有了这篇博文。
1、YOLO 环境配置 1.1 安装 CUDA 和 cudnn 参考之前写的 博客 ,按其中步骤安装即可。这里安装的是 version 为 11.2 的cuda。
1.2 安装 pytorch-gpu 去 torch官网 寻找与自己 cuda 版本相对应的 pytorch,这里我没有找到对应 cuda-11.2 版本的torch安装命令,于是选择了安装 cuda-11.1 的torch(自己安装torch的cuda版本应不能超过电脑的 cuda 版本 )
1 pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
建议先安装 torch,再安装 yolo;若先安装 yolo,系统会自行安装 torch-cpu,还需卸载
1.3 安装 YOLOv8 git 拉取 ultralytics: YOLOv8 🚀 Ultralytics 同步更新官方最新版 YOLOv8 (gitee.com) :
1 git clone https://gitee.com/monkeycc/ultralytics.git
进入 ultralytics 目录内,安装 yolo 及相关依赖
验证是否安装成功
1 2 import ultralytics
1 2 Ultralytics YOLOv8.0.230 � Python-3.8.8 torch-1.8.1+cu111 CUDA:0 (NVIDIA GeForce GTX 1050 Ti, 4096MiB)
1.4 下载预权重 下载训练模型,推荐yolov8s.pt或者yolov8n.pt,模型小,下载快,在gitee或者github下方readme里面,下载完成后,将模型放在主文件夹下
yolov8s.pt下载地址:yolov8s.pt
yolov8n.pt下载地址:yolov8n.pt
1.5 测试环境 1 yolo predict model=yolov8n.pt source ='ultralytics/assets/bus.jpg'
1/1 E:\myProject\ultralytics\ultralytics\assets\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 80.1ms 1 2 3 Speed: 0.0ms preprocess, 80.1ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 480)
2、安装数据标注工具 2.1 标注工具基本介绍 这里只介绍两种标注工具:labelimg、labelme;LabelMe和LabelImg都是用于图像标注的工具,但它们有一些不同之处:
开发者和平台: LabelMe:LabelMe是由麻省理工学院(MIT)开发的在线标注工具,允许用户标注图像,并支持多种标注格式。 LabelImg:LabelImg是由Tzutalin开发的开源工具,它是一个基于Python的图像标注工具,可以在本地使用,支持多种格式的图像标注。 功能: LabelMe:LabelMe提供了一些高级的标注功能,如实例分割(不仅限于矩形框标注)和复杂形状标注 的能力。 LabelImg:LabelImg相对简单,适用于一般的对象检测任务,支持常见的矩形标注和类别标签 。 使用场景和灵活性: LabelMe:适合需要更复杂标注需求(如实例分割)的项目 ,同时需要在线协作或访问的团队。 LabelImg:适合简单的对象检测标注需求 ,更适合个人或小团队在本地使用。 选择使用哪个工具取决于你的具体需求和标注的复杂程度。如果你需要更高级的标注功能并且团队需要在线协作,LabelMe可能更适合;而如果你只需要简单的对象检测标注,LabelImg可能更加方便。这里我们只是进行简单的目标检测,选择使用LabelImg;当然你也可以选用LabelMe,注意LabelMe标注生成的文件为json,还需额外脚本将其生成txt才能用作yolo训练。
2.2 LabelMe安装 参考 GitHub主页 安装:
1 2 3 4 5 6 conda create --name=labelme python=3
运行命令,启动 labelimg
2.3 LabelImg安装 参考 github主页 安装步骤安装:
1 2 3 4 5 6 7 conda install pyqt=5
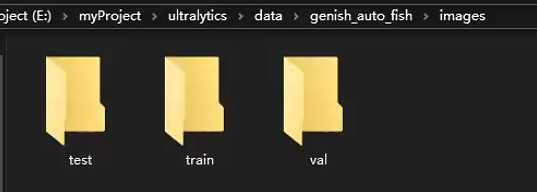
3、训练模型 3.1 创建数据加载配置文件 新建data文件夹(可自定义),再在data目录下新建images, labels, data.yaml
YOLOv8 从环境搭建到推理训练_yolov8 predict-CSDN博客
教程:超详细从零开始yolov5模型训练_yolo训练-CSDN博客
📌images目录下存放数据集的图片文件
📌labels目录下存放txt标准格式标签
📌yaml文件用来存放一些目录信息和标志物分类
3.2 创建数据集 步骤(YOLO):
在 data/predefined_classes.txt 文件中定义将用于训练的类别列表。 使用上述说明构建并启动。 在工具栏中的“保存”按钮正下方,点击“PascalVOC”按钮切换到YOLO格式。 您可以使用“打开/Open”或“打开/OpenDIR”来处理单个或多个图像。处理完单个图像后,请点击保存。 YOLO格式的txt文件将保存在与图像同名的文件夹中。名为“classes.txt”的文件也将保存在该文件夹中。 “classes.txt”定义了YOLO标签所引用的类别列表。 注意:
在处理图像列表时,您的标签列表不应该在处理过程中更改。当您保存一张图像时,classes.txt也会被更新,而之前的注释不会被更新。在保存为YOLO格式时,不应使用“默认类别”功能,它不会被引用。保存为YOLO格式时,“difficult”标志会被丢弃。
3.3 数据集划分 在前面创建的imges及labels文件夹下存放划分后的数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import os, shutil, randomfrom tqdm import tqdm""" 标注文件是yolo格式(txt文件) 训练集:验证集:测试集 (7:2:1) """ def split_img (img_path, label_path, split_list ):try :'./genish_auto_fish' '/images/train' '/images/val' '/images/test' '/labels/train' '/labels/val' '/labels/test' except :print ('文件目录已存在' )for img in all_img]int (train * len (all_img_path)))'\\' )[-1 ]) for img in train_img]for img in train_img]'\\' )[-1 ]) for label in train_label]for i in tqdm(range (len (train_img)), desc='train ' , ncols=80 , unit='img' ):int (val / (val + test) * len (all_img_path)))for img in val_img]for i in tqdm(range (len (val_img)), desc='val ' , ncols=80 , unit='img' ):for img in test_img]for i in tqdm(range (len (test_img)), desc='test ' , ncols=80 , unit='img' ):def _copy (from_path, to_path ):def toLabelPath (img_path, label_path ):'\\' )[-1 ]'.' )[0 ] + '.txt' return os.path.join(label_path, label)if __name__ == '__main__' :'./genish_auto_fish/imagesAll' './genish_auto_fish/labelsAll' 0.7 , 0.2 , 0.1 ]
脚本运行后,生成将标注好的数据随机划分到各自的文件夹中,label同理
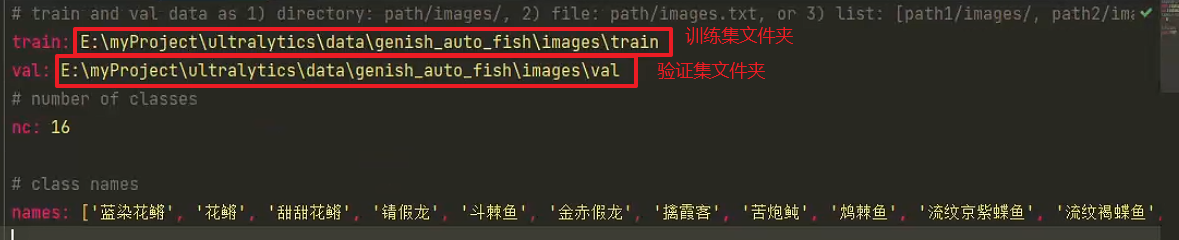
在对应yaml配置文件中配置好自己数据集的相关信息,以备训练
3.4 模型训练 1 yolo task=detect mode=train model=yolov8s.yaml data=mydata_tuomin/tuomin.yaml epochs=100 batch=4 device=0
以上参数解释如下:
📌task:选择任务类型,可选['detect', 'segment', 'classify', 'init']。
📌mode: 选择是训练、验证还是预测的任务类型,可选['train', 'val', 'predict']。
📌model: 选择yolov8不同的模型配置文件,可选yolov8s.yaml、yolov8m.yaml、yolov8x.yaml等,也可选择已经训练好的预训练权重(yolov8s.pt、yolov8m.pt)。
选择.pt和.yaml的区别(YOLOv8训练参数详解 )
.pt类型的文件是从预训练模型的基础上进行训练。若我们选择 yolov8n.pt这种.pt类型的文件,其实里面是包含了模型的结构和训练好的参数的,也就是说拿来就可以用,就已经具备了检测目标的能力了,yolov8n.pt能检测coco中的80个类别。假设你要检测不同种类的狗,那么yolov8n.pt原本可以检测狗的能力对你训练应该是有帮助的,你只需要在此基础上提升其对不同狗的鉴别能力即可。但如果你需要检测的类别不在其中,例如口罩检测,那么就帮助不大。 .yaml文件是从零开始训练。采用yolov8n.yaml这种.yaml文件的形式,在文件中指定类别,以及一些别的参数。📌data: 选择生成的数据集配置文件,即前面的fish.yaml
📌epochs:训练的轮次数量,指的就是训练过程中整个数据集将被迭代多少次。
📌batch:每批图像数量(-1为自动批大小);一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
📌device:可以使用device参数指定训练设备。如果没有传递参数,并且有可用的GPU,则将使用GPU device=0,否则将使用device=cpu。
更详细的介绍,可前往查阅 yolov8技术文档的训练章节( 训练 - Ultralytics YOLOv8 文档 )
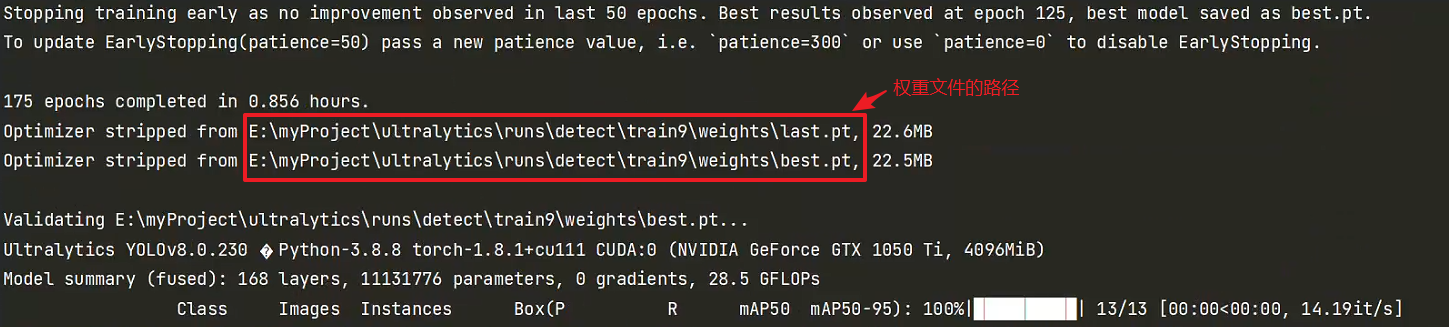
训练完成后,系统会输出权重储存路径:
4、 对原神窗口进行实时目标检测 网上查询了窗口图像采集的方案,最终选定pywin32库进行程序窗口的图像采集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import win32gui, win32ui, win32conimport cv2import numpyfrom ultralytics import YOLOif __name__ == '__main__' :"原神" None , window_name)'best.pt' )print (left, top, right, bot)'im_opencv' )while True :0 , 0 ), (width, height), mfcDC, (0 , 0 ), win32con.SRCCOPY)True )'uint8' )4 )0 , 0 ), fx=0.5 , fy=0.5 )"im_opencv" , result[0 ].plot()) 10 )if key & 0xFF == ord ('q' ): print ('正在退出窗口' )break
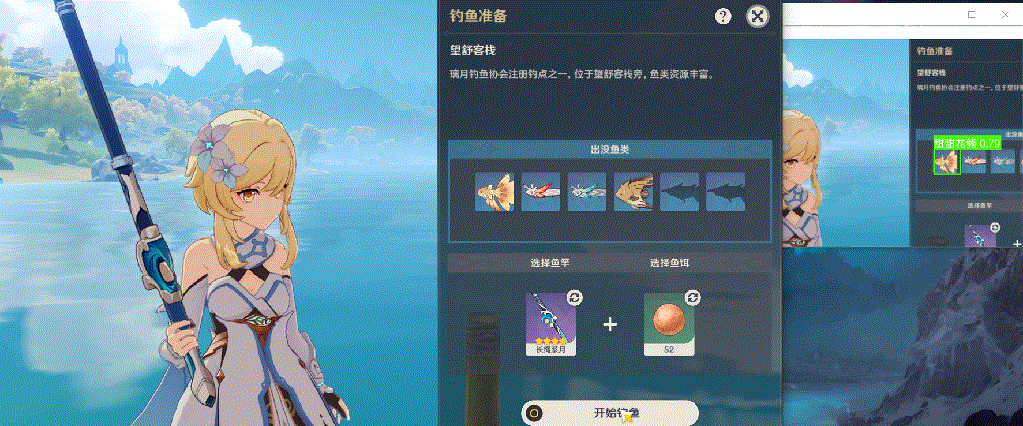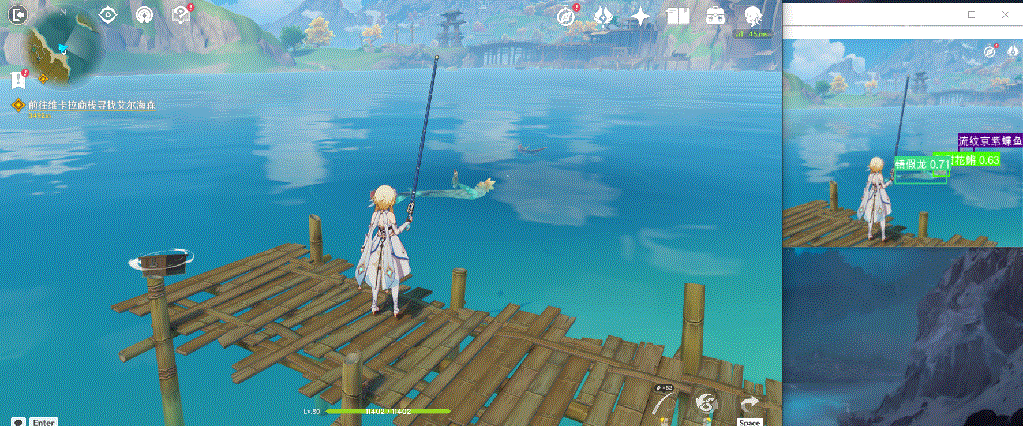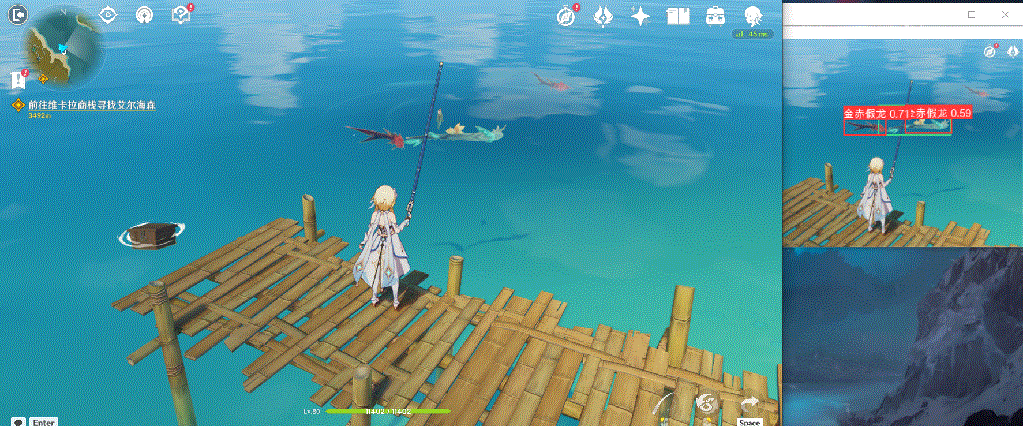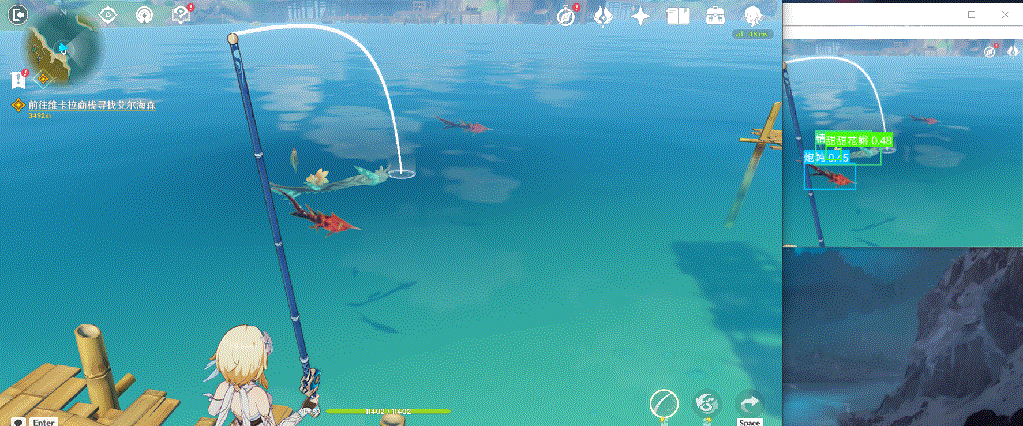
下面展示一下最终效果,由于本人精力有限,只采集了150张图片作为数据集,整体识别效果一般;但是通过这么一个实现过程,确实能够帮助大家入门yolo
Reference:
Ultralytics YOLOv8 文档 win10下Tensorflow与Pytorch安装教程-CSDN博客 PyTorch文档 labelImg README zh YOLOv8 从环境搭建到推理训练_yolov8 predict-CSDN博客 教程:超详细从零开始yolov5模型训练_yolo训练-CSDN博客 YOLOv8训练参数详解(全面详细、重点突出、大白话阐述小白也能看懂)_yolov8参数-CSDN博客